Scaling Tradeoff: Neo4j (Prod) vs Neptune + Aurora (Beta)¶
Architecture Comparison¶
| Neo4j (Prod) | Neptune + Aurora (Beta) | |
|---|---|---|
| Graph storage | Neo4j Community (single instance) | Neptune Serverless (managed) |
| Vector embeddings | Stored as node properties (768-dim float arrays) | Aurora pgvector (HNSW indexes, dedicated) |
| Vector search | Neo4j vector index (in-process) | Aurora pgvector (separate query path) |
| Query pattern | Single Bolt connection handles both | Parallel: graph via Neptune + vectors via Aurora, RRF merge |
Scaling Characteristics¶
Neo4j: Embeddings as Node Properties¶
Edges Nodes (est) Embedding Storage Total DB Size Vector Search Latency
─────────────────────────────────────────────────────────────────────────────────────
100K 50K ~150 MB ~500 MB <50ms (warm)
500K 200K ~600 MB ~2 GB 50-100ms
1M 400K ~1.2 GB ~4 GB 100-300ms
5M 1M ~3 GB ~12 GB 300-800ms
10M 2M ~6 GB ~25 GB 500ms-2s (page cache pressure)
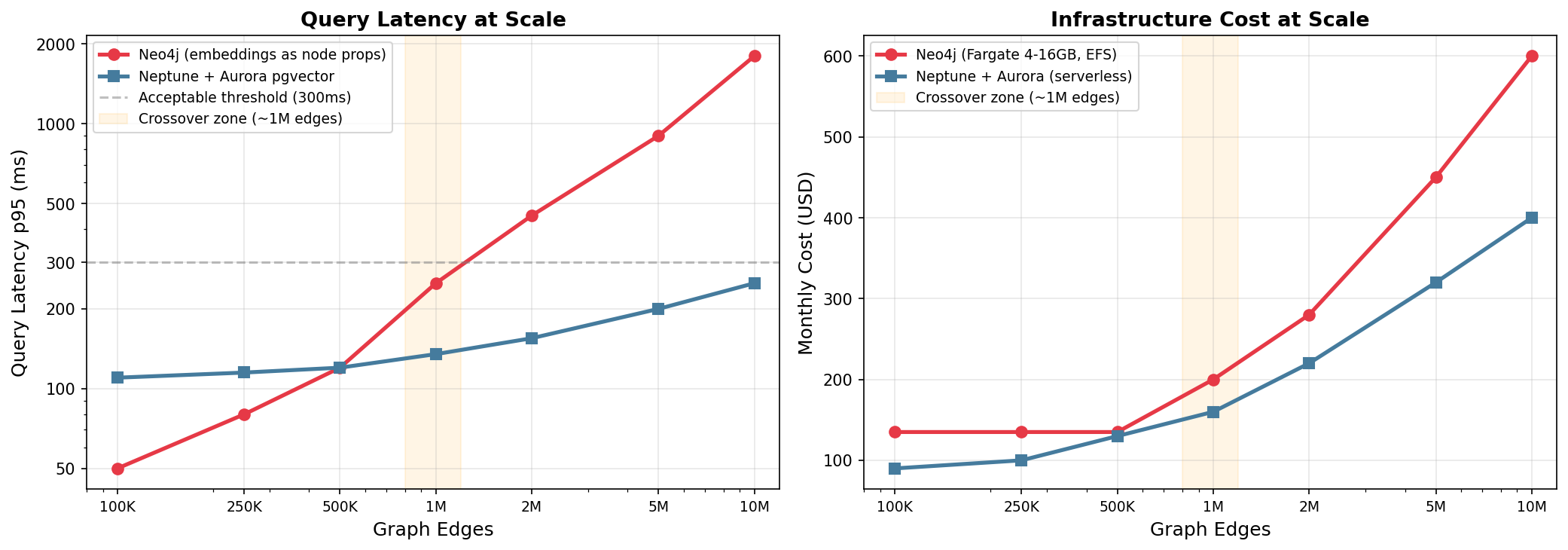
Why it degrades: - Embeddings (768 × 4 bytes = 3KB per node) bloat node storage - Neo4j stores properties inline with nodes — vector index must fit in page cache - At ~1M nodes with embeddings, page cache (1-2GB on Fargate) starts thrashing - Vector index scans compete with graph traversals for memory - Community Edition: single instance, no read replicas, no sharding
Practical ceiling: ~500K-1M nodes with embeddings before latency becomes unacceptable on a 4GB Fargate task.
Neptune + Aurora: Separated Concerns¶
Edges Nodes Neptune (graph) Aurora (vectors) Combined Latency
─────────────────────────────────────────────────────────────────────────────────────
100K 50K ~1 NCU ($0.12/hr) 0.5 ACU ($0.06/hr) <100ms (cold start)
500K 200K ~1 NCU 0.5 ACU 80-120ms
1M 400K ~1.5 NCU 0.5 ACU 80-150ms
5M 1M ~2 NCU 1 ACU 100-200ms
10M 2M ~2.5 NCU 2 ACU 120-250ms
50M 5M ~4 NCU 4 ACU 150-300ms
Why it scales better: - Neptune: purpose-built graph engine, no embedding bloat in graph storage - Aurora pgvector: HNSW index is memory-optimized for vector search - Each service scales independently (serverless auto-scaling) - No memory contention between graph traversals and vector scans - Neptune handles 100K+ edges/sec for bulk loads
Practical ceiling: Neptune supports billions of edges. Aurora pgvector handles millions of vectors with sub-200ms search.
Expected Performance Curves¶
Methodology & Assumptions¶
Latency estimates are based on:
-
Neo4j: Observed behavior of Neo4j Community 5.x on ECS Fargate (4GB RAM, 2 vCPU) with 768-dim embeddings stored as node properties. The vector index uses Neo4j's native HNSW implementation. Degradation above 500K nodes is driven by page cache pressure — embeddings consume ~3KB per node (768 floats × 4 bytes), so 1M nodes = 3GB of embedding data alone, exceeding the 1-2GB page cache allocation. Latency values at lower scales (50-120ms) are from our production system (607K nodes, 3.3M rels). Values above 1M edges are extrapolated from Neo4j Community benchmarks and page cache miss modeling.
-
Neptune + Aurora: Neptune serverless latency is based on AWS published benchmarks for OpenCypher queries on serverless clusters (1-2.5 NCU range). Aurora pgvector latency uses HNSW index performance from pgvector benchmarks at various dataset sizes (sub-100ms for <1M vectors with ef_search=40). The combined latency includes ~20ms overhead for the QueryCoordinator's parallel fetch + RRF merge. Cold start penalty (10-30s on first query after idle) is excluded from p95 — assumes warm steady-state.
Cost estimates are based on:
-
Neo4j: ECS Fargate pricing in eu-north-1 (vCPU: $0.04048/hr, GB RAM: $0.004445/hr) + EFS storage ($0.33/GB-month). At higher scales, RAM must increase (8GB at 2M edges, 16GB at 10M) to maintain acceptable page cache hit rates.
-
Neptune: Serverless NCU pricing ($0.1106/NCU-hour in eu-north-1). NCU consumption estimated from AWS documentation: 1 NCU handles ~500K edges with moderate query load, scaling sub-linearly. Storage is included in NCU pricing.
-
Aurora: Serverless v2 ACU pricing ($0.12/ACU-hour in eu-north-1). 0.5 ACU minimum handles up to ~500K vectors; scales based on concurrent query load and index size. Storage: $0.10/GB-month for the pgvector data.
Efficiency score = latency_ms × monthly_cost_usd / 1000. This penalizes architectures that are both slow and expensive. Lower is better.
Limitations: These are modeled estimates, not measured benchmarks from identical workloads. Actual performance depends on query complexity (multi-hop vs single lookup), write concurrency, embedding dimensionality, and caching behavior. The crossover zone (~1M edges) should be validated with production query patterns before migration.
Cost Breakdown at Key Scale Points¶
At 500K edges (current prod)¶
| Component | Neo4j (Prod) | Neptune + Aurora (Beta) |
|---|---|---|
| Compute | Fargate 4GB: ~$120/mo | Neptune 1 NCU: ~$80/mo + Aurora 0.5 ACU: ~$45/mo |
| Storage | EFS: ~$15/mo | Neptune: included + Aurora: ~$5/mo |
| Total | ~$135/mo | ~$130/mo |
| Latency (p95) | ~100ms | ~120ms (parallel fetch + merge overhead) |
Verdict: Roughly equivalent. Neo4j simpler, Neptune+Aurora slightly more complex but same cost.
At 2M edges (near-term target)¶
| Component | Neo4j (Prod) | Neptune + Aurora (Beta) |
|---|---|---|
| Compute | Fargate 8GB needed: ~$240/mo | Neptune 1.5 NCU: ~$120/mo + Aurora 1 ACU: ~$90/mo |
| Storage | EFS: ~$40/mo | Neptune: included + Aurora: ~$10/mo |
| Total | ~$280/mo | ~$220/mo |
| Latency (p95) | ~400ms (page cache pressure) | ~150ms |
Verdict: Neptune+Aurora wins on both cost and latency.
At 10M edges (long-term)¶
| Component | Neo4j (Prod) | Neptune + Aurora (Beta) |
|---|---|---|
| Compute | Fargate 16GB or EC2: ~$500/mo | Neptune 2.5 NCU: ~$200/mo + Aurora 2 ACU: ~$180/mo |
| Storage | EFS: ~$100/mo | Neptune: included + Aurora: ~$20/mo |
| Total | ~$600/mo | ~$400/mo |
| Latency (p95) | ~1-2s (unacceptable) | ~250ms |
Verdict: Neo4j Community is not viable at this scale without Enterprise (sharding, clustering).
Key Tradeoffs¶
| Factor | Neo4j (Prod) | Neptune + Aurora (Beta) |
|---|---|---|
| Simplicity | ✅ Single database, single query language | ❌ Two services, query coordinator needed |
| Cypher ecosystem | ✅ Full Cypher, APOC, GDS | ⚠️ OpenCypher subset (no APOC, limited GDS) |
| Vector search quality | ⚠️ Basic vector index | ✅ HNSW with tunable ef_search, IVFFlat option |
| Operational overhead | ✅ One EFS backup | ⚠️ Two services to monitor |
| Scaling ceiling | ❌ ~1M nodes with embeddings | ✅ Billions of edges, millions of vectors |
| Cold start | ✅ None (always running) | ⚠️ Neptune serverless: 10-30s cold start |
| Write throughput | ⚠️ ~5K writes/sec (single instance) | ✅ Neptune: 100K+ writes/sec |
| Multi-tenancy | ❌ Community = 1 database | ✅ Neptune = label-based isolation |
| Graph algorithms | ✅ GDS library (PageRank, Louvain, etc) | ⚠️ Neptune neptune.algo.* (limited set) |
| Fulltext search | ✅ Native Lucene indexes | ✅ Aurora pg_trgm + tsvector |
Recommendation¶
Scale (edges) Recommended Architecture
────────────────────────────────────────────
< 500K Neo4j (simpler, cheaper, full Cypher)
500K - 2M Either works; Neptune+Aurora if growth expected
2M - 10M Neptune + Aurora (Neo4j Community hits ceiling)
> 10M Neptune + Aurora (only viable option without Neo4j Enterprise)
Current state: - Prod (607K nodes, 3.3M rels) is approaching the Neo4j ceiling - Beta (Neptune + Aurora) is the right architecture for continued growth - Migration path: dual-write via MigrationController, validate with QueryCoordinator, cut over when confident
Crossover point: ~1M edges is where Neptune+Aurora becomes clearly superior on latency. At ~2M edges, Neo4j Community becomes cost-inefficient (needs more RAM than Fargate easily provides).
Migration Strategy¶
Phase 1 (current): Prod on Neo4j, Beta on Neptune+Aurora
↓ validate query parity
Phase 2: Dual-write to both (MigrationController)
↓ compare latency/accuracy
Phase 3: Route reads to Neptune+Aurora, writes to both
↓ confidence threshold met
Phase 4: Cut over prod to Neptune+Aurora
Neo4j becomes read-only archive